
Visión computacional: RF-DETR
Arquitectura, optimizacion y diferencias frente a YOLO y DETR

Este artículo analiza RF-DETR dentro del ecosistema actual de visión computacional (computer vision), específicamente en deteccion y segmentacion de objetos. El objetivo es entender las diferencias estructurales frente a YOLO (You Only Look Once) y a modelos basados en DETR (Detection Transformer), y evaluar qué cambia en términos de arquitectura y optimización.
La comparación se organiza en tres niveles:
Diferencias en la arquitectura de cada modelo.
Implicancias en latencia y eficiencia.
Impacto en el ciclo de diseño y despliegue de modelos.
Estado actual
La deteccion de objetos en visión computacional (computer vision) ha evolucionado hacia tres lineas principales. Aunque todas buscan localizar y clasificar objetos en una imagen, difieren en cómo estructuran el problema. Para entender esas diferencias es útil definir tres conceptos:
Redundancia: Producir multiples predicciones para un mismo objeto. Por ejemplo, un unico auto puede aparecer marcado por varias cajas superpuestas.
Asignacion: El mecanismo que empareja las predicciones del modelo con los objetos reales durante el entrenamiento.
Postprocesamiento: Pasos adicionales aplicados despues de que la red genera sus salidas, como eliminar duplicados o ajustar resultados.
Con estos conceptos claros, podemos diferenciar las tres familias principales.
Modelos de prediccion densa: la familia YOLO
Los modelos YOLO (You Only Look Once) generan muchas predicciones en paralelo sobre distintas regiones de la imagen. La redundancia es intencional: el modelo produce multiples bounding boxes candidatas y luego filtra.
El filtrado se realiza mediante NMS (Non-Maximum Suppression), un algoritmo que elimina cajas superpuestas conservando la de mayor confianza segun un umbral de solapamiento medido con Intersection over Union (IoU). NMS es un paso de postprocesamiento externo al modelo.

Durante el entrenamiento, la asignacion es local: cada celda o anchor se asocia a un objeto cercano segun reglas geométricas.
En este enfoque:
Se acepta redundancia.
Se corrige mediante NMS.
La asignacion es local.
Modelos basados en DETR
DETR (Detection Transformer) reformula el problema como prediccion de un conjunto (set prediction). En lugar de producir muchas predicciones y luego filtrarlas, intenta generar directamente un conjunto coherente de objetos.
La arquitectura utiliza un encoder-decoder Transformer. El decoder opera sobre un conjunto fijo de object queries aprendibles, donde cada query intenta representar un objeto.

Durante el entrenamiento se emplea Hungarian matching, un algoritmo de asignacion bipartita que empareja predicciones y objetos reales de forma uno a uno. Esto obliga al modelo a producir una unica prediccion por objeto.
Como consecuencia, en principio no requiere NMS como componente central.
En este enfoque:
Se evita la redundancia desde el diseño.
No depende de NMS.
La asignacion es global y uno a uno.
Detectores open-vocabulary
Una tercera linea integra modelos vision-language. Estos incorporan un text encoder y combinan representaciones visuales y textuales mediante mecanismos de cross-attention.
")
La diferencia principal no es el manejo de duplicados, sino la ampliacion del espacio semantico: permiten detectar categorias fuera de un conjunto cerrado.
Esto implica:
Procesamiento adicional en inferencia.
Mayor costo computacional.
Dependencia del preentrenamiento multimodal.
Diferencias entre arquitecturas
La diferencia principal entre las tres arquitecturas es cómo parametrizan el espacio de salida, es decir, la representación latente sobre la que se define el proceso de búsqueda de objetos.
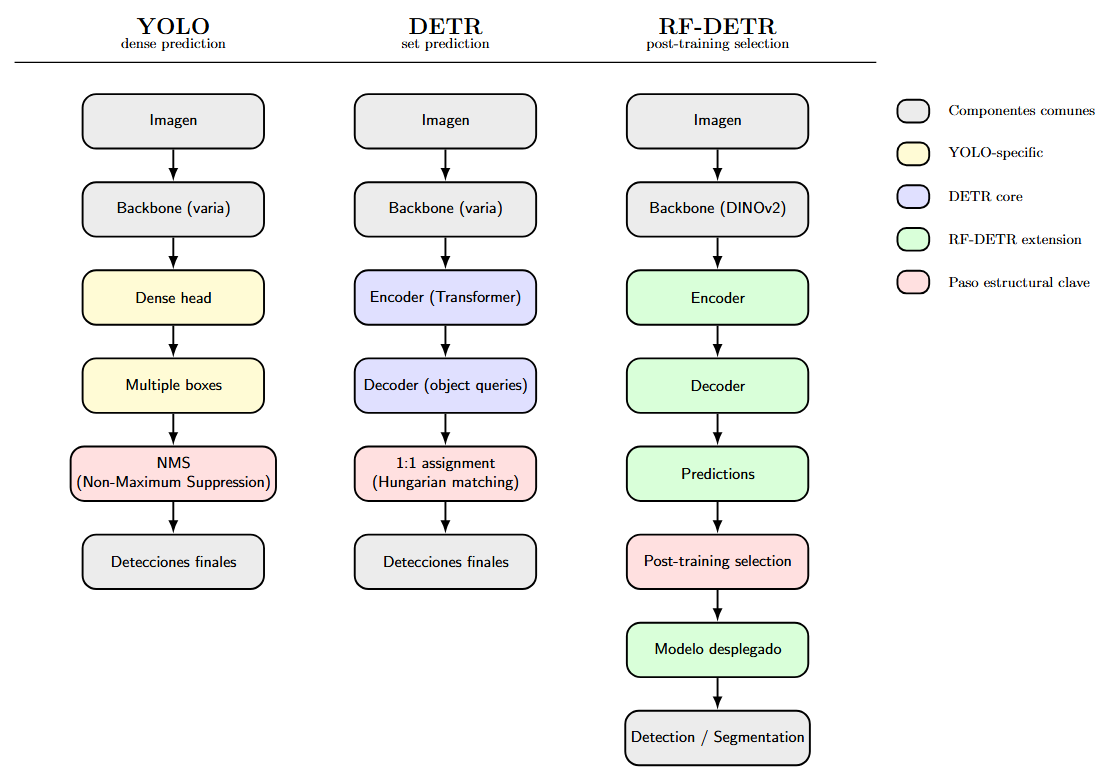
Consideremos una imagen con tres objetos: un auto parcialmente tapado por otro objeto, un peatón pequeño al fondo y una bicicleta que se cruza visualmente con el auto. Es un caso típico: objetos de distinto tamaño, parcialmente visibles y con regiones que se superponen.

En una arquitectura tipo YOLO, distintas regiones de la imagen pueden activarse sobre el mismo objeto. El auto puede generar varias cajas candidatas porque varias celdas “ven” partes distintas del mismo objeto. El modelo no evita esa duplicación. Produce múltiples hipótesis y luego NMS decide cuál conservar según el solapamiento (IoU). La ambigüedad se resuelve después de predecir.
En DETR, la situación es distinta. El modelo dispone de un conjunto fijo de representaciones latentes (object queries). Cada una debe explicar, como máximo, un objeto. Durante entrenamiento, la asignación uno a uno obliga a que el auto sea representado por una única predicción. Si dos queries intentan representar el mismo objeto, una será penalizada. La ambigüedad se resuelve dentro del modelo, no en un paso externo.
RF-DETR mantiene la formulación de DETR como predicción de un conjunto con asignación uno a uno. La diferencia es que no entrena una única arquitectura fija.
Se entrena una superred con pesos compartidos que contiene múltiples subconfiguraciones. Después del entrenamiento, se puede seleccionar una configuración más pequeña o más grande sin reentrenar desde cero.
Conclusiones e implicaciones
El objetivo de este artículo no es comparar cuál modelo obtiene mejor resultado en un benchmark específico, sino entender cómo cada arquitectura define el problema y qué implica esa definición para nuestro sistema.
YOLO, DETR y RF-DETR son más que variaciones técnicas. Representan decisiones distintas sobre:
Cómo se parametriza el espacio de salida.
Dónde se controla la redundancia.
En qué etapa se fijan las restricciones del sistema.
YOLO coloca parte de la coherencia en inferencia. DETR la internaliza en el aprendizaje. RF-DETR mantiene esa formulación, pero introduce flexibilidad en cómo se concreta la arquitectura entrenada.
El principal trade-off es estructura versus control.
Elegir un enfoque implica decidir:
Si se prefiere una arquitectura fija y explícita.
Si se prioriza coherencia estructural desde el entrenamiento.
Si se necesita capacidad de adaptación posterior sin redefinir la lógica de predicción.
La elección debería basarse en lo que esperamos que el sistema haga y bajo qué restricciones debe operar.